
1. Introduction
Prominent vendors employ fuzzing as part of their secure development practices.
More recently, security auditors and open-source developers have also started to use fuzzing to gauge the security of commodity software packages and provide some suitable forms of assurance to end-users.
- 不幸的是,研究人员和从业人员在模糊测试方面的大量工作也带有进展受阻的警告信号。
- 超出其源代码和设计手册的范围
- there has been an observable fragmentation in the terminology used by various fuzzers.
- reduces the size of a crashing input
- test case minimization
- test case reduction
- crash minimization
- reduces the size of a crashing input
2. SYSTEMIZATION, TAXONOMY, AND TEST PROGRAMS(系统化、分类学和测试程序)
fuzzing terminology and a unified model of fuzzing :
- Definition 1 (Fuzzing):
- Fuzzing is the execution of the PUT(Program Under Test) using input(s) sampled from an input space (the “fuzz input space”) that protrudes the expected input space of the PUT.
- 三个注释依次进行。首先,尽管模糊输入空间包含期望的输入空间可能是常见的,但这并不是必要的- -前者包含不在后者中的输入就足够了。其次,在实践中,模糊测试几乎必然要运行多次迭代;因此,上述"重复处决"的写法在很大程度上仍然是准确的。第三,抽样过程并不一定是随机的,我们将在§ 5中看到。
- Fuzzing is the execution of the PUT(Program Under Test) using input(s) sampled from an input space (the “fuzz input space”) that protrudes the expected input space of the PUT.
- Definition 2 (Fuzz Testing): Fuzz testing is the use of fuzzing to test if a PUT violates a security policy.
- Definition 3 (Fuzzer): A fuzzer is a program that performs fuzz testing on a PUT.
- Definition 4 (Fuzz Campaign):A fuzz campaign is a specific execution of a fuzzer on a PUT with a specific security policy.
- Definition 5 (Bug Oracle): A bug oracle is a program, perhaps as part of a fuzzer, that determines whether a given execution of the PUT violates(违背) a specific security policy.
- We refer to the algorithm implemented by a fuzzer simply as its “fuzz algorithm”. Almost all fuzz algorithms depend on some parameters beyond (the path to) the PUT. Each concrete setting of the parameters is a fuzz configuration:
- Definition 6 (Fuzz Configuration): A fuzz configuration of a fuzz algorithm comprises the parameter value(s) that control(s) the fuzz algorithm.
- 模糊器通常会维护一个种子池,并且会随着模糊测试活动的进展而逐渐扩充和演变。最后,每个配置都可以保存一些数据。例如,基于覆盖率的模糊器可以在每个配置中存储覆盖率信息。
相关期刊:
- ACM Conference on Computer and Communications Security (CCS) – 是计算机和通信安全领域的一个顶级会议,主要研究网络、通信、计算机系统和软件的安全问题。
- IEEE Symposium on Security and Privacy (S&P) – 是安全和隐私领域的一个顶级学术会议,研究包括软件、硬件、网络、移动设备和云计算在内的智能系统的安全和隐私问题。
- Network and Distributed System Security Symposium (NDSS) – 是网络和分布式系统安全领域的一个重要会议,关注网络协议、网络安全体系结构和互联网等方面的安全问题。
- USENIX Security Symposium (USEC) – 是计算机系统和网络安全领域的一个重要会议,主要包括操作系统安全、网络协议安全、移动设备安全等相关问题。
- ACM International Symposium on the Foundations of Software Engineering (FSE) – 是软件工程领域的一个重要会议,主要关注软件开发过程中基础理论、方法和工具的研究和应用。
- IEEE/ACM International Conference on Automated Software Engineering (ASE) – 是自动化软件工程领域的一个重要会议,主要关注使用计算机科学和数学的原理来自动化软件开发的方法和技术。
- International Conference on Software Engineering (ICSE) – 是软件工程领域的一个著名学术会议,主要关注软件开发的方法、工具和技术,包括软件驱动的组织行为、过程和方法。
fuzz testing only differentiates itself from software testing in that fuzz testing is security related.
Fuzz Testing Algorithm:
模糊测试的通用算法,其通用性可以包含现在已有的模糊测试技术:

Fuzz Testing:
- Part One: Process
- 用户向 PR E P R O C E S S 提供一组模糊配置作为输入,并返回一组可能修改的模糊配置。根据模糊算法,PR E P R O C E S S 可以执行各种操作,例如将检测代码插入 PUT,或测量种子文件的执行速度。见§3。
- Part Two:
- Continue
- CON T I N U E 将一组模糊配置 C 作为输入,并输出一个布尔值,指示是否应进行新的模糊迭代。此函数对于模拟白盒模糊器很有用,当没有更多路径可供发现时,这些模糊器可以终止。
- Schedule (生成模糊配置)
- SC H E D U L E 将当前的模糊配置集、当前经过的时间和超时 tlimit 作为输入,并选择要用于当前模糊迭代的模糊配置。见§4。
- InputGen (生成测试用例)
- IN P U TGE N 将模糊配置作为输入,并返回一组具体的测试用例 tcs 作为输出。生成测试用例时,IN P U TGE N 使用 conf 中的特定参数。一些模糊器使用 conf 中的种子来生成测试用例,而其他模糊器使用模型或语法作为参数。见§5。
- InputEval
- IN P U TEV A L 将一个模糊配置 conf、一组测试用例 tcs 和一个 bug oracle Obug 作为输入。它在 tcs 上执行 PUT,并使用 bug oracle Obug 检查执行是否违反了安全策略。然后它输出发现的错误集 B' 和有关每个模糊测试运行 execinfos 的信息,这些信息可用于更新模糊测试配置。我们假设 Obug 嵌入到我们的模型模糊器中。见§6
- ConfUpdate
- CON FUP D A T E 采用一组模糊配置 C、当前配置 conf 以及有关每个模糊运行 execinfos 的信息(执行结果)作为输入。它可能会更新模糊配置集 C。例如,许多灰盒模糊器会根据 execinfos 减少 C 中模糊配置的数量。见§7。
- Continue
- 参数含义:
- C 表示 模糊配置 – Fuzz Configuration
- 超时设置
- B' 错误集
execinfos 里面有哪些信息
Chat,给的回答。
Fuzzing 中,execinfos 是指执行信息,它包含了程序在运行过程中的一些关键信息,如地址、偏移量、调用堆栈、寄存器值等,在漏洞分析过程中非常有用。举例来说,execinfos 可以包含以下几个信息:
- Program Counter (PC) – 表示当前指令的地址;
- Stack Pointer (SP) – 表示当前堆栈指针的值;
- Instruction Pointer (IP) – 表示程序中下一条将要执行的指令的地址;
- Memory Address – 表示被访问的内存地址;
- Function Return Address – 表示函数将要返回时的地址;
- Register Values – 表示在执行过程中所有寄存器的值;
- System Call Arguments – 表示系统调用的参数。
在 Fuzzing 过程中,通过将随机生成的输入传递给待测的程序,并记录其执行信息,可以更加全面地模拟真实的程序运行环境,并在其中查找可能存在的漏洞。
- three groups based on the granularity of semantics a fuzzer observes in each fuzz run.
- Black-box Fuzzer
- 无法得知 PUT (Program Under Test)内部信息
- White-box Fuzzer
- 白盒模糊测试 通过分析 PUT 的内部结构和执行 PUT 时收集的信息来生成测试用例。因此,白盒模糊器能够系统地探索 PUT 的状态空间。术语白盒模糊测试由 Godefroid在 2007 年引入,指的是动态符号执行 (DSE),它是符号执行的变体。
- 在动态符号执行(dynamic symbolic execution)中,符号执行和具体执行同时运行,其中具体程序状态用于简化符号约束,例如具体化系统调用。此外,白盒模糊测试也被用来描述采用污点分析的模糊器。白盒模糊测试的开销通常比黑盒模糊测试的开销高得多。这部分是因为 DSE 实现通常采用动态检测和 SMT 求解 。虽然 DSE 是一个活跃的研究领域 ,但许多 DSE 不是白盒模糊器,因为它们的目的不是寻找安全漏洞。
- 待阅读的相关论文(得是引用这些论文的新论文,经典论文也太老了)
- S. Anand, E. K. Burke, T. Y. Chen, J. Clark, M. B. Cohen, W. Grieskamp, M. Harman, M. J. Harrold, and P. Mcminn, “An orchestrated survey of methodologies for automated software test case generation,” Journal of Systems and Software, vol. 86, no. 8, pp. 1978–2001, 2013.
- E. J. Schwartz, T. Avgerinos, and D. Brumley, “All you ever wanted to know about dynamic taint analysis and forward symbolic execution (but might have been afraid to ask),” in Proceedings of the IEEE Symposium on Security and Privacy, 2010, pp. 317–331.
- Grey-box Fuzzer
– 灰盒模糊器可以获得 PUT 和/或其执行的一些内部信息。与白盒模糊器不同,灰盒模糊器不推理 PUT 的完整语义;相反,他们可以对 PUT 执行轻量级静态分析和/或收集有关其执行的动态信息,例如代码覆盖率。灰盒模糊器依靠近似的、不完美的信息来提高速度并能够测试更多的输入。现代模糊器中,AFL和Vuzzer是该类示范。- Chatgpt: 灰盒模糊器可以根据程序的源代码或二进制文件来生成测试用例,这种方法结合了黑白盒fuzzer的优点,既可以尽可能地遍历代码路径,又可以避免过多的无效测试用例。灰盒模糊器通常采用一些静态或动态分析方法来获取程序的部分执行信息和随机测试用例的优化相关信息。这种方法常常可以达到良好的测试用例覆盖率和发现更多漏洞的目的。
- Black-box Fuzzer
下图是,19年为止,流行的Fuzz工具。
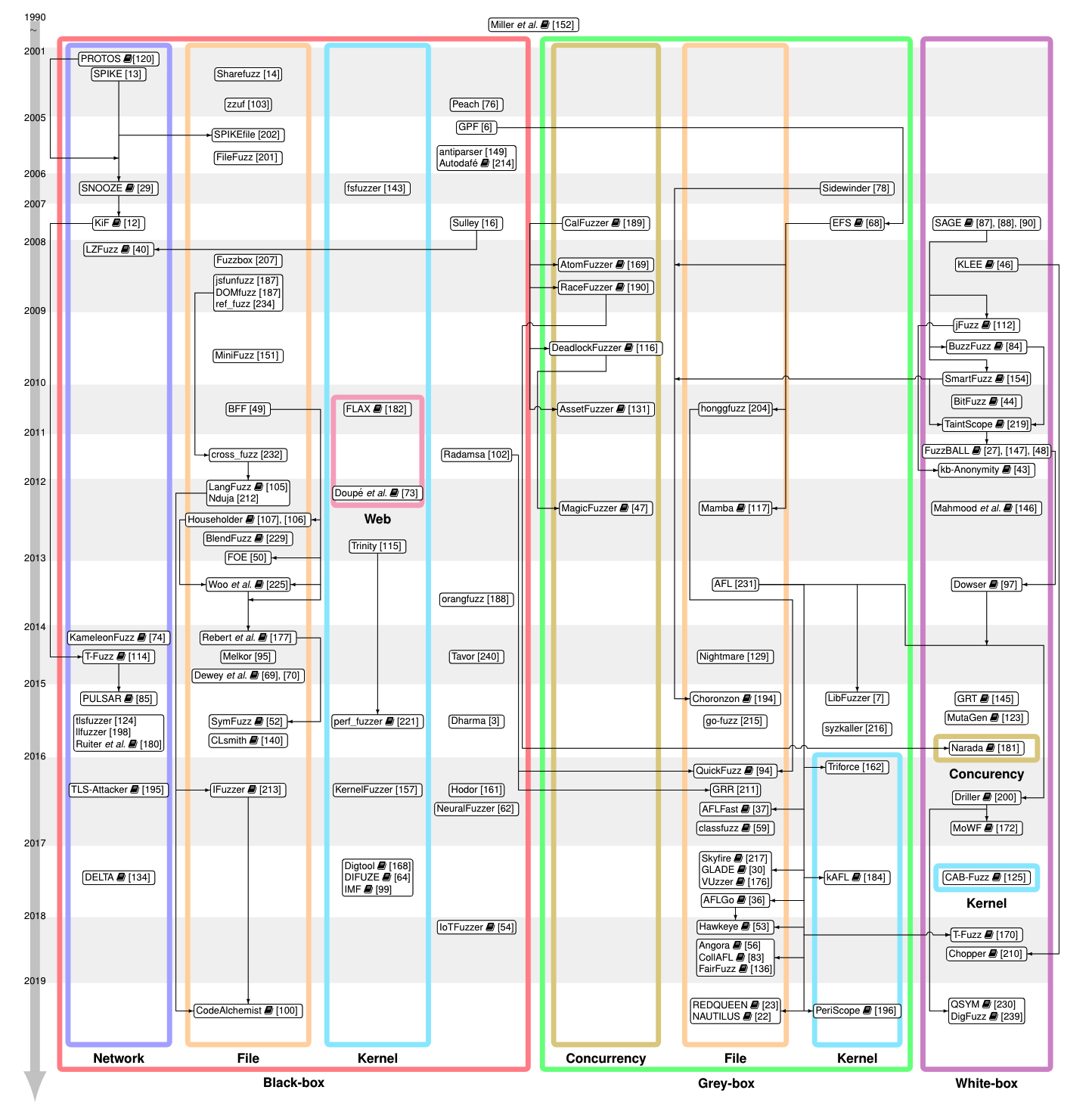
此外,作者还对其中的工具进行详细分类,需要关注的是其中的分类,且在19年就存在结合其他技术(如,符号执行、污点分析、AI)的fuzz 工作。
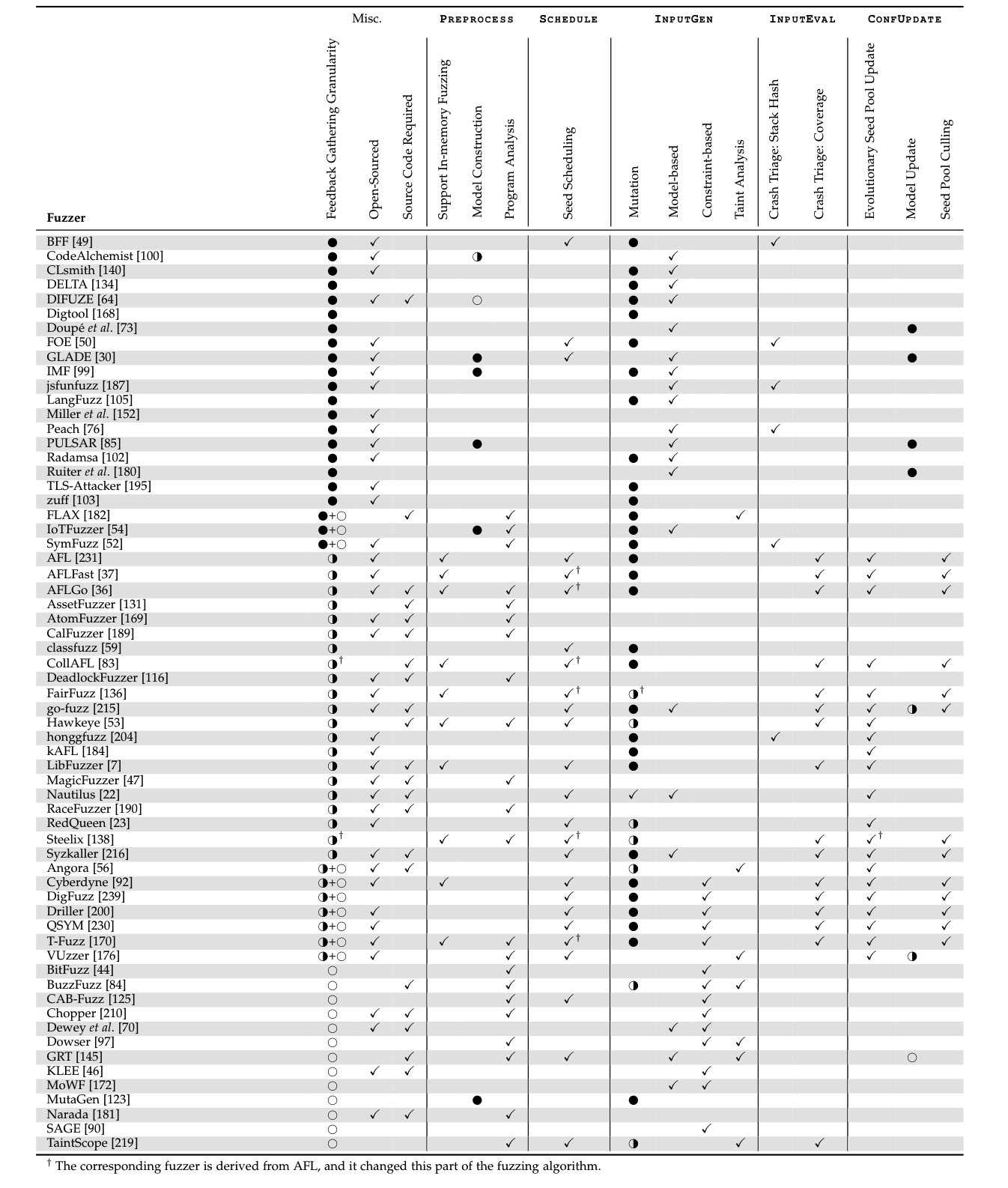
Seed 的初步理解 (结合Chatgpt):
Fuzzing Test 算法中的 Schedule 中生成的 conf。
3 Prepocess
- 一些fuzz 会修改 fuzz_configurations 在 第一次 fuzz 之前。
- 检查 PUT
- 清除潜在的冗余配置
- 修剪种子以及生成驱动程序应用程序
- 实施(Instrumentation)
- 与黑盒模糊测试不同,灰盒模糊测试和白盒模糊测试都可以在IN P U TEV A L执行模糊运行时检测PUT以收集执行反馈(参见§ 6 ),或者在运行时模糊内存内容。采集的信息量定义了模糊器(即黑盒、白盒或灰盒)的颜色。
- 插桩技术
- 静态:在 PUT Preprocess 之前
- 插桩直接写在源代码中或者IR中,运行开销小;但若需要对第三方库同样采用静态插桩,那也需要进行重新编译。
- 动态:在 PUT Preprocess 运行时
- 即便存在开销大的问题,但优势在于可以方便插桩。
- 混合模式:一个给定的模糊器可以支持多种类型的仪表。例如,AFL通过修改的编译器支持源代码级别的静态插桩,或者通过QEMU支持二进制级别的动态插桩。当使用动态插桩时,AFL既可以插桩( 1 ) PUT本身的可执行代码,这是默认设置,也可以插桩( 2 ) PUT和任何外部库(使用AFL _ INST _ LIBS选项)的可执行代码。第二个选项- -插装所有遇到的代码- -可以为外部库中的代码报告覆盖信息,从而提供更完整的覆盖图。然而,这也会促使AFL在外部库函数中模糊附加路径。
- 静态:在 PUT Preprocess 之前
- 1 Execution Feedback
- 灰盒模糊测试通常将执行反馈作为输入来演化测试用例。AFL及其后代通过在PUT中插桩每个分支指令来计算分支覆盖率。但是,它们将分支覆盖信息存储在一个比特向量中,会造成路径碰撞(不太理解)。Coll AFL 最近通过引入一个新的敏感路径哈希函数来解决这个问题。同时,LibFuzzer 和Syzkaller 使用节点覆盖率作为其执行反馈。Honggfuzz 允许用户选择使用哪种执行反馈。
- AFLplusplus/AFLplusplus: The fuzzer afl++ is afl with community patches, qemu 5.1 upgrade, collision-free coverage, enhanced laf-intel & redqueen, AFLfast++ power schedules, MOpt mutators, unicorn_mode, and a lot more! (github.com)
- 2 In- Memory Fuzzing(性能优化,相当于热启动 PUT)
- 在测试大型程序时,有时希望只对PUT的一部分进行模糊测试,而不需要为每次模糊迭代重新生成一个进程,以最小化执行开销。例如,复杂的(例如, GUI)应用在接受输入之前往往需要几秒钟的处理时间。对此类程序进行模糊测试的一种方法是在GUI初始化后对PUT进行快照。为了模糊一个新的测试用例,在将新测试用例直接写入内存并执行之前,可以恢复内存快照。同样的直觉也适用于涉及客户端和服务器之间大量交互的模糊网络应用。这种技术被称为内存模糊技术(In- Memory Fuzzing)。
- 内存API模糊测试(in-memory API fuzzing):
- 一些模糊测试器在不恢复每次迭代后PUT的状态的情况下在函数中执行内存中的模糊测试。 我们称这种技术为内存中的API模糊测试。 例如,AFL有一个名为persistent mode的选项,它在循环中重复执行内存中API模糊测试而不重新启动进程。 在这种情况下,AFL忽略了在同一次执行中多次调用该函数可能产生的副作用。
- 存在的问题:
- 为目标函数构建有效的调用上下文并不总是可行的
- 可能存在未在多个函数调用中捕获的副作用
- 内存中 API 模糊测试的可靠性主要取决于入口点函数,找到这样的函数是一项具有挑战性的任务。
- 3 Thread Scheduling
- 争用条件错误可能难以触发,因为它们依赖于可能很少发生的非确定性行为。但是,检测也可用于通过显式控制线程的调度方式来触发不同的非确定性程序行为。现有工作表明,即使是随机调度线程也可以有效地发现竞争条件错误。
- 多线程引发的问题 (新的上下文信息),确实也需要关注,应该有该方面的系统研究。
- Seed Selection;种子(测试样例)选择
- 在模糊测试中,Seed Selection的中文翻译是“种子(测试用例)选择”。Seed Selection是一项关键的技术,它指的是在模糊测试中选择有效的测试用例进行最优的覆盖率和发现率。
- 应该使用哪些种子进行模糊测试?这种减小初始种子池大小的问题被称为种子选择问题?
- MP3 播放器 可以使用的 测试样例,理论上无限多。如何高效触发,得需要合适的种子和生成算法。
- 在模糊测试中,种子(seed)指的是一组用作测试用例的输入数据,这些数据是用来启动模糊测试批次的起始数据。种子包含了模糊测试的开始测试的基础用例,模糊测试过程中根据需要可以对种子进行变异,生成更多的测试用例。
- 相关方法:
- Method 1 (常规且有效) :一种常见的方法是找到一组最小的种子,以最大化覆盖指标,例如节点覆盖率,这个过程称为计算最小集。
- current set of configurations C consists of two seeds s1 and s2 that cover the following addresses of the PUT: {s1 → {10, 20} , s2 → {20, 30}}.
- If we have a third seed s3 → {10, 20, 30} that executes roughly as fast as s1 and s2, one could argue it makes sense to fuzz s3 instead of s1 and s2, since it intuitively tests more program logic for half the execution time cost.
- 🌟 模糊器使用各种不同的覆盖度量标准:
- AFL的minset基于分支覆盖率,每个分支有一个对数计数器。
- Honggfuzz根据执行指令、执行分支和唯一基本块数量计算覆盖率。
- Method 1 (常规且有效) :一种常见的方法是找到一组最小的种子,以最大化覆盖指标,例如节点覆盖率,这个过程称为计算最小集。
- Seed Trimming:种子修剪
- throughput: 吞吐量
- 在模糊测试中,throughput(吞吐量)指的是在单位时间内运行测试用例或执行某个操作的数量,通常以每秒执行的次数(TPS,transactions per second)来度量。
- 较小的种子可能会占用较少的内存并带来更高的吞吐量。因此,一些模糊测试程序在进行模糊测试之前尝试缩小种子的大小,这被称为种子修剪。种子修剪可以在PREPROCESS的主要模糊测试循环之前发生,也可以作为CO N FUP D A T E的一部分发生。一个值得注意的使用种子修剪的模糊测试程序是AFL,它使用其代码覆盖率仪器来迭代地删除一部分种子,只要修改后的种子实现相同的覆盖率。
- throughput: 吞吐量
- 准备驱动程序
- 当难以直接对 PUT 进行模糊测试时,准备一个用于模糊测试的驱动程序是有意义的。
4 SCHEDULING
- SCHEDULING
- conf <- Schedule(C, t_e, t_l)
- The Fuzz Configuration Scheduling (FCS) Problem:
- 模糊配置调度 (FCS) 问题
- 调度的目标是分析有关配置的当前可用信息,并选择一个可能导致最有利结果的信息,例如,找到最多数量的独特错误,或最大化生成输入集所获得的覆盖率.
- 存在冲突:模糊测试中的Fuzz Configuration Scheduling(FCS)问题,是指如何在有限的资源条件下,在大量待测试的参数配置组合中选择最合适的配置进行模糊测试。
- 解决FCS问题可以采用各种策略和算法。例如,可以采用启发式搜索算法(如遗传算法、模拟退火算法等)对参数空间进行优化搜索,找到最佳配置组合。另外,采用策略迭代、主动学习等自动化技术也可以对FCS问题进行解决。
- FCS Algorithm:
- 黑盒
- 在黑盒设置中,唯一可以使用的信息是配置的模糊结果,即找到的崩溃和漏洞的数量以及目前花费的时间。
- A. D. Householder and J. M. Foote, “Probability-based parameter selection for black-box fuzz testing,” CERT, Tech. Rep. CMU/SEI-2012-TN-019, 2012.
- a configuration with a higher observed success rate
(#bugs / #runs)
- a configuration with a higher observed success rate
- M. Woo, S. K. Cha, S. Gottlieb, and D. Brumley, “Scheduling black-box mutational fuzzing,” in Proceedings of the ACM Conference on Computer and Communications Security, 2013, pp. 511–522.
- Unknown Weights (WCCP/UW), 明确保持该概率的上限随着时间的推移而衰减。
- multi-armed bandit (MAB) problems
- 更快的模糊配置使模糊器能够以更快的速度收集更多的唯一漏洞,或者更快地降低其未来的成功概率上限。
- 改变了BFF中雪崩式运行的编排方式,从每个配置选择中的固定模糊迭代次数(BFF术语中的“epochs”)到每个选择的固定时间。
- 灰盒
- evolutionary algorithm(进化算法 – 算法簇)
- [Evolutionary Algorithm] 进化算法简介 – Poll的笔记 – 博客园 (cnblogs.com)
- 直观地说,EA 维护一组配置,每个配置都有一些“适应度”值。 EA 选择合适的配置并将它们应用于遗传转换,例如突变和重组以产生后代,这些后代可能会在以后成为新的配置。假设是这些生成的配置更可能适合。要在 EA 上下文中理解 FCS,我们需要定义 (i) 什么使配置合适,(ii) 如何选择配置,以及 (iii) 如何使用所选配置。作为高级近似,在执行控制流边缘的配置中,AFL 认为包含最快和最小输入的配置是合适的(AFL 术语中的“最喜欢的”)。 AFL 维护一个配置队列,它从中选择下一个合适的配置,就好像队列是循环的一样。一旦选择了一个配置,AFL 就会对其进行模糊测试,运行次数基本上是恒定的。
- 相关项目
- AFLFast
- AFLGo
- FairFuzz
- evolutionary algorithm(进化算法 – 算法簇)
- 白盒(该论文没有主动详细描述,提供了参考链接,即 E. Bounimova, P. Godefroid, and D. Molnar, “Billions and billions of constraints: Whitebox fuzz testing in production,” in Proceedings of the International Conference on Software Engineering, 2013, pp. 122–131. )
- 黑盒
5 Input Generation
传统上,模糊器分为基于生成或基于突变的模糊器。基于生成的模糊器根据描述 PUT 预期输入的给定模型生成测试用例。我们在本文中将此类模糊器称为基于模型的模糊器。另一方面,基于突变的模糊器通过改变给定的种子输入来生成测试用例。基于突变的模糊器通常被认为是无模型的,因为种子只是示例输入,即使数量很大,它们也不能完全描述 PUT 的预期输入空间。在本节中,我们将根据底层测试用例生成 (IN P U TGE N) 机制对模糊器使用的各种输入生成技术进行解释和分类。
- Model-based (Generation-based) Fuzzers (生成/模型,黑盒多)
- 基于模型的模糊器根据描述 PUT 可能接受的输入或执行的给定模型生成测试用例,例如精确描述输入格式的语法或不太精确的约束,例如识别文件类型的魔术值。
- Predefined Model(预定义模型)
- 目前有工具支持用户自定义模型,来生成测试样例
- Backus-Naur form (EBNF)
- 针对语言、语法、协议,也可以通过利用约束逻辑编程来生成不仅语法正确而且语义多样的测试用例
- 目前有工具支持用户自定义模型,来生成测试样例
- Inferred Model (推断模型)
- 不依赖预定义或用户提供的模型而受到欢迎
- Model Inference in
PreProcess- 一些模糊器将模型推断为预处理步骤。
- 这些约束是使用静态分析和动态分析计算的。
- 数据驱动的方法来推断概率上下文相关语法,然后使用它来生成一组新的种子。
- 分析系统 API 日志来学习内核 API 模型,并生成使用推断模型调用一系列 API 调用的 C 代码。
- 将 JavaScript 代码分解为“代码块”,并计算组装约束,这些约束描述了何时可以将不同的代码块组装或合并在一起以产生语义上有效的测试用例。
- 使用基于神经网络的机器学习技术从给定的一组测试文件中学习模型,并从推断模型生成测试用例。
- Model Inference in
ConfUpdate- 其他模糊器可能会在每次模糊迭代后更新其模型。
- 从程序生成的一组捕获的网络数据包中自动推断网络协议模型。然后使用学习到的网络协议对程序进行模糊测试。
- PULSAR 内部构建了一个状态机,并将哪个消息令牌与状态相关联。此信息稍后用于生成覆盖状态机中更多状态的测试用例。
- 通过观察 I/O 行为来推断 Web 服务状态机的方法。然后使用推断的模型来扫描 Web 漏洞。
- 从一组 I/O 样本中合成一个上下文无关的语法,并使用推断的语法对 PUT 进行模糊测试。
- 其他模糊器可能会在每次模糊迭代后更新其模型。
- Encoder Model
- Fuzzing is often used to test decoder programs which parse a certain file format.
- Many file formats have corresponding encoder programs, which can be thought of as an implicit model of the file format.
- 没看明白
- mutation-based fuzzers (突变/无模型,灰盒多)
- 大多数无模型模糊器使用种子,它是 PUT 的输入,以便通过修改种子来生成测试用例。种子通常是 PUT 支持的类型的结构良好的输入:文件、网络数据包或一系列 UI 事件。通过只改变有效文件的一小部分,通常可以生成一个新的测试用例,该用例大部分有效,但也包含异常值以触发 PUT 崩溃。种子变异的方法有很多种,我们在下面描述常见的方法。
- Bit-Flipping (位翻转)
- 一些模糊器只是简单地翻转固定数量的比特,而其他模糊器则确定随机翻转的比特数。为了随机突变种子,一些模糊器使用了一个用户可配置的参数,称为突变率,它决定了 IN P U TGE N 的单次执行要翻转的位位置的数量。假设一个模糊器想要从给定的 N 中翻转 K 个随机位位种子。
- SymFuzz 利用白盒程序分析来推断每个种子的良好突变率。
- 感觉不太适用我的想法?🤔️
- Arithmetic Mutation (算术突变)
- 为啥感觉这些方法是针对特定方案的,适用与底层上的随机。
- AFL和honggfuzz 包含另一种突变操作,其中它们将选择的字节序列视为整数,并对该值执行简单的算术运算。然后使用计算出的值来替换所选的字节序列。关键的想法是通过一个小的数限制变异的影响。例如,AFL从一个种子中选择一个4字节值,并将该值视为整数i。然后,它将种子中的值替换为i±r,其中r是随机生成的一个小整数。r的范围取决于模糊器,并且通常是可配置的用户。在AFL中, 默认范围为:0≤r<35
- Block-based Mutation(基于块的突变)
- 块是种子的字节序列
- 它涉及在种子中随机插入、删除、替换、排列、调整大小和交换字节块。
- Dictionary-based Mutation (基于字典的突变)
- 使用具有语义权重的预定义值(如0或-1)来突变整数
- White-box Fuzzers
- 白盒模糊器也可以分为基于模型或无模型的模糊器。例如,传统的动态符号执行不需要像基于突变的模糊器那样的任何模型,一些符号执行器利用输入模型(例如输入语法)来指导符号执行器,也有利用白盒程序分析来查找有关 PUT 接受的输入的信息,以便将其用于黑盒或灰盒模糊测试。
- Dynamic Symbolic Execution (动态符号执行)
- 也称为 concolic (concrete + symbolic) testing
- 经典符号执行运行一个以符号值作为输入的程序,它代表所有可能的值。当它执行 PUT 时,它构建符号表达式而不是评估具体值。每当它到达条件分支指令时,它在概念上会分叉两个符号解释器,一个用于真分支,另一个用于假分支。对于每条路径,符号解释器为它在执行期间遇到的每条分支指令建立路径公式(或路径谓词)。如果存在执行所需路径的具体输入,则路径公式是可满足的。可以通过查询 SMT 求解器来生成具体的输入以获取路径公式的解。动态符号执行是传统符号执行的一种变体,其中符号执行和具体执行同时运行。
- 重点:在PUT过程中,构建表达式,然后运行符号执行,查看是否存在可行解。具体的执行状态可以帮助降低符号约束的复杂性。
- 缺陷:动态符号执行速度较慢,因为它涉及检测和分析 PUT 的每条指令。
- 解决方法:
- 为了应对高昂的成本,一种常见的策略是缩小其使用范围;例如,让用户指定代码中不感兴趣的部分,或者在混合测试和灰盒模糊测试之间交替。
- 通过实施快速混合执行引擎来改进灰盒和白盒模糊测试之间的集成。
- 通过首先估计使用灰盒模糊测试执行每条路径的概率来优化灰盒和白盒模糊测试之间的切换,然后让其白盒模糊器专注于被认为最具挑战性的路径灰盒模糊测试。
- Guided Fuzzing (引导模糊测试)
- 一些模糊器利用静态或动态程序分析技术来增强模糊测试的有效性。这些技术通常涉及两个阶段的模糊测试
- 用于获取有关 PUT 的有用信息的昂贵程序分析
- 在先前分析的指导下生成测试用例。
- 使用细粒度的污点分析来查找“热字节”,这些字节是流入关键系统调用或 API 调用的输入字节。
- 在编译期间执行静态分析,以基于启发式查找可能包含错误的循环。具体来说,它会查找包含指针取消引用的循环。然后,它通过污点分析计算 12 个输入字节与候选循环之间的关系。最后,Dowser 运行动态符号执行,同时仅使关键字节成为符号字节,从而提高性能。
- 利用静态和动态分析技术从 PUT 中提取控制和数据流特征,并使用它们来指导输入生成。
- 通过使用污点分析将每个路径约束与相应的字节相关联来改进“hot bytes”的想法。然后,它执行受梯度下降算法启发的搜索,以引导其突变解决这些约束。
- 一些模糊器利用静态或动态程序分析技术来增强模糊测试的有效性。这些技术通常涉及两个阶段的模糊测试
- PUT Mutation
- 模糊测试中存在一个实际挑战:
- 绕过校验和验证
- 解决方案:
- 提出了一种校验和感知的模糊测试技术,该技术通过污点分析识别校验和测试指令,并修补 PUT 以绕过校验和验证。一旦发现程序崩溃,他们就会为输入生成正确的校验和,以生成使未修改的 PUT 崩溃的测试用例。
- etc.
- 模糊测试中存在一个实际挑战:
6 Input Evaluation
- 生成输入后,模糊器对输入执行 PUT,并决定如何处理结果执行。这个过程称为输入评估。尽管执行 PUT 的简单性是模糊测试具有吸引力的原因之一,但有许多与输入评估相关的优化和设计决策会影响模糊器的性能和有效性,我们将在本节中探讨这些考虑因素。
- Bug Oracles (漏洞预言)
- 检查在Input Evaluation状态中,是否触发了漏洞,介绍Fuzz 常见的检测漏洞和对应的方法
- Memory and Type Safety
- 作者主要说明了内存类的错误
- Undefined Behaviors
- 一种安全问题,代码中存在未定义的问题
- Input Validation
- 提及 XSS 和 SQL
- Semantic Difference(语义差异)
- 它通常用于发现语义错误,即程序逻辑或意义中的错误。
- Execution Optimizations (执行优化)
- fork : 允许每个新的模糊迭代从一个已经初始化的进程中分叉出来。
- 内存模糊测试是另一种优化执行速度的方法
- 无论确切的机制如何,加载和初始化 PUT 的开销都会在多次迭代中分摊
- Triage (分流)
- Triage is the process of analyzing and reporting test cases that cause policy violations.
- deduplication 重复数据删除
- 重复数据删除是从输出集中删除与另一个测试用例触发相同错误的任何测试用例的过程。理想情况下,重复数据删除会返回一组测试用例,其中每个测试用例都会触发一个独特的错误。
- 目前在实践中使用三种主要的重复数据删除实现:堆栈回溯哈希、基于覆盖率的重复数据删除和语义感知重复数据删除。
- Stack Backtrace Hashing
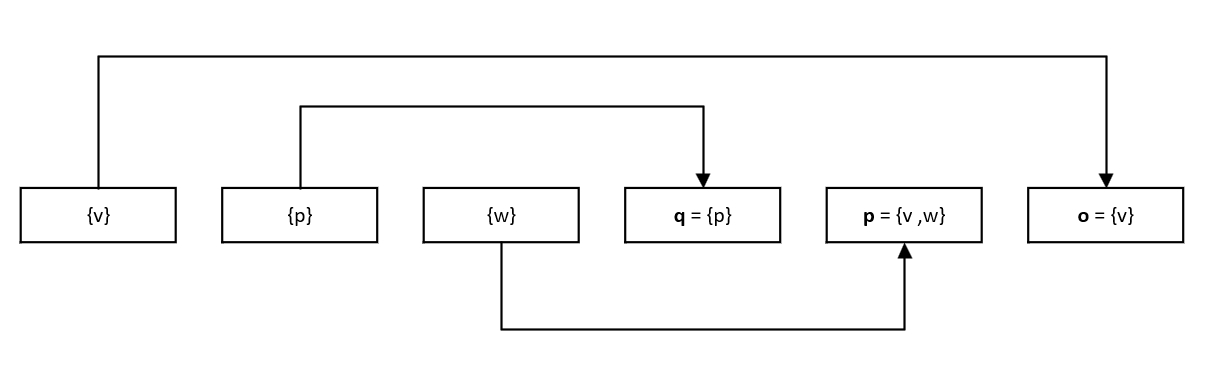
- 其中自动化工具记录崩溃时的堆栈回溯,并根据该回溯的内容。例如,如果程序在执行函数 foo 中的一行代码时崩溃,并且具有调用堆栈 main → d → c → b → a → foo(见图 2),则堆栈回溯哈希实现 n = 5将该测试用例与其他崩溃执行组合在一起,这些执行的回溯以 d → c → b → a → foo 结尾。
- Coverage-based Deduplication
- AFL 是一种流行的灰盒模糊器,它采用高效的源代码检测来记录 PUT 每次执行的边缘覆盖率,并测量每个边缘的粗命中计数。作为灰盒模糊器,AFL 主要使用此覆盖信息来选择新的种子文件。然而,它也导致了一个相当独特的重复数据删除方案。如其文档所述,如果 (i) 崩溃覆盖了以前未见过的边缘,或 (ii) 崩溃未覆盖所有早期崩溃中存在的边缘,则 AFL 认为崩溃是唯一的。
- 语义感知重复数据删除(Backward analysis)
- 根据从每次崩溃的反向数据流分析中恢复的语义执行崩溃分类。具体来说,RETracer 通过分析故障转储(核心转储)来检查是哪个指针导致了崩溃,并递归地识别哪个指令为其分配了错误的值。它最终会找到一个具有最大帧级别的函数,并“责怪”该函数。 blamed 函数可用于集群崩溃。作者表明,他们的技术成功地将数百万个 Internet Explorer 错误删除为一个。相比之下,堆栈哈希将相同的崩溃分类为大量不同的组。
- Prioritization and Exploitability 优先级和可利用性
- One of the first exploitability ranking systems was Microsoft’s !exploitable which gets its name from the !exploitable WinDbg command name that it provides. !exploitable employs several heuristics paired with a simplified taint analysis . It classifies each crash on the following severity scale: EXPLOITABLE > PROBABLY_EXPLOITABLE > UNKNOWN > NOT_LIKELY_EXPLOITABLE, in which x > y means that x is more severe than y.
- test case minimization 测试用例最小化
- 测试用例最小化是识别触发违规所必需的违规测试用例部分的过程,并可选择生成比原始测试用例更小更简单但仍会导致违规的测试用例。
- 注意 test case minimization 与 seed trimming
- 尽管测试用例最小化和种子修剪(参见 3.3,第 8 页)在概念上是相似的,因为它们旨在减小输入的大小,但它们是不同的,因为最小化器可以利用 bug oracle。
7 CONFIGURATION UPDATING
- CONFUPDATE 函数在区分黑盒模糊器与灰盒和白盒模糊器的行为方面起着至关重要的作用。如算法1中所述,CONFUPDATE 函数可以根据当前模糊测试运行期间收集的配置和执行信息修改配置集(C)。
- 黑盒:除了评估 bug oracle 之外,黑盒模糊器不执行任何程序自省,因此他们通常不修改 C,因为他们没有收集任何允许他们修改它的信息1。
- 白盒、灰盒:相比之下,灰盒和白盒模糊器的特点是它们更复杂地实现了 CO N FUP D A T E 函数,这允许它们合并新的模糊配置,或删除可能已被取代的旧配置。
- Evolutionary Seed Pool Update
- 进化算法 (EA) 是一种基于启发式的方法,涉及生物进化机制,例如突变、重组和选择。在模糊测试的背景下,EA 维护着一个有前途的个体(即种子)的种子池,随着新个体的发现,该种子池在模糊测试活动的过程中不断发展。尽管 EA 的概念相对简单,但它构成了许多灰盒模糊器的基础 。选择要变异的种子的过程和变异过程本身分别在 §4.3 和 §5 中详细介绍。可以说,EA 最重要的步骤是向配置集 C 添加新配置,这发生在模糊测试的 CO N FUP D A T E 步骤中。
- 大多数基于 EA 的模糊器使用节点或分支覆盖作为适应度函数:如果测试用例发现新节点或分支,则将其添加到种子池中。由于可达路径的数量可能比种子数量大几个数量,因此种子池旨在成为所有可达路径的多样化子选择,以表示 PUT 的当前探索。另请注意,不同大小的种子池可以具有相同的覆盖率(如第 7 页第 3.2 节所述)。
- 🌟 适应度函数 (fitness function)
- 适应度函数(fitness function)用于评估自动生成的输入是否对目标程序产生了有用的、有意义的结果。适应度函数通常是衡量测试用例“好”与“坏”的标准,因为“好”的测试用例往往能够更好地触发目标程序中的漏洞或错误,从而更有可能得到有意义或有用的结果。
- Maintaining a Minset
- 创建新的模糊测试配置的能力带来了创建过多配置的风险。用于减轻这种风险的常见策略是维护一个最小集,或最小化的测试用例集,以最大化覆盖率指标。
Note
- 还是得实践和阅读最新的文章,大致理解了Fuzz的技术框架,以及普遍的Fuzz算法。
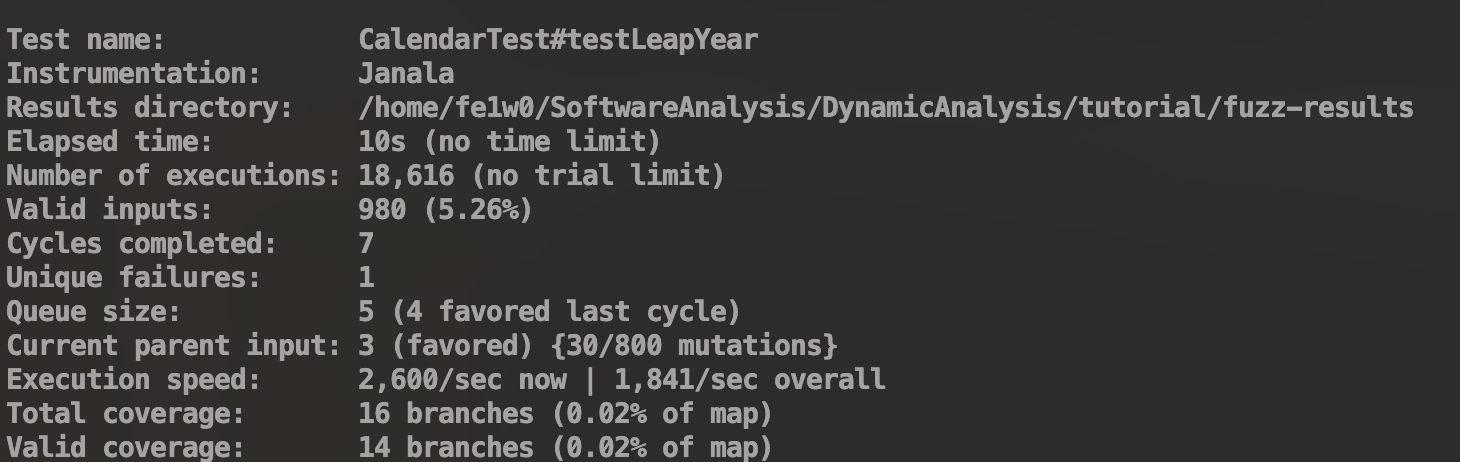

Fuzz永远的神!我们现在在做固件的fuzz,难得批爆!(´இ皿இ`)