1. 问题背景
随着计算机技术的发展,当前的软件系统的规模和复杂度不断提高,一般采用动态程序分析或静态程序分析,对软件系统进行分析,包含漏洞检测、错误检测、并行优化等方面。在分析C/C++(Java)等程序时,静态分析技术首先需要解决如何解析程序中的间接引用信息,包括间接数据流信息(C/C++程序的指针解引用信息、Java程序中的对象引用访问信息)和间接控制流信息(C/C++ 程序的函数指针信息、Java程序的虚函数调用信息)。
指针分析是一种静态程序分析技术,它的目标是静态确定一个指针变量能够指向哪些地址(变量或函数的存储位置),也就是静态确定一个指针变量在程序运行时所有可能的值。指针分析以程序源代码(或某种中间代码表达)作为输入,输出该程序所包含的指针指向信息。由于指针(引用)在C/C++(Java)程序中被广泛使用,许多静态程序依据分析技术需要依据指针指向信息来解析程序中包含的间接引用,指针分析的结果直接影响其他静态程序分析技术的有效性。
基于合并(unification-based)的Steensgaard算法和基于包含(inclusion-based)的Andersen算法是两个经典的流不敏感上下文不敏感的指针分析算法。 其中, Andersen算法是流不敏感上下文不敏感指针分析中精度最高的算法。
流敏感分析(flow-sensitve analysis)与流非敏感分析(flow-insensitive analysis),这两者的主要区别在于在流非敏感分析发生语句交换,并不影响分析结果,抽象数据后的数据保存为全局数据,反之在流敏感分析中会产生不同的结果,每个结点保存一份抽象数据。
以下面代码的符号分析为例,来描述流敏感分析(flow-sensitve analysis)与流非敏感分析(flow-insensitive analysis)在分析结果上的区别。
对于流敏感分析而言,语句1的分析结果是a为正,分析结果存储在语句1中,语句2的分析结果是a为负,分析结果存储在语句2中;对于流非敏感分析而言,分析语句1时,全局信息中存储a的符号信息($a: [正]$),分析语句2时,全局信息中存储a的符号信息进行合并($a: [正, 负]$)。
上下文敏感分析(context-sensitive analysis)与上下文非敏感分析(context-insensitive analysis),主要引用与过程间分析中(interprocedural analysis),考虑是否将当前程序的上下文信息(函数参数,全局变量等)引入到调用函数中,上下文敏感分析的引入会带来精度上的提升,但可能会导致分析速度的下降。
若要对下面代码进行常量分析,如分析出函数a的输出是否为常量,则必须在调用串(Call String)中,引入变量g的常量信息。
int g = some_value;
int a(){
int v = 1;
return b(v);
}
int b(int v) {
return v + g
}
Andersen算法首次提出,是Lars Ole Andersen在1994年的Program Analysis and Specialization For the C Programming Language中,在后面的指针分析算法中不断更新和发展,并将Andersen算法思想扩张到其他指针分析算法中,如基于流敏感的指针分析算法。
2. Andersen算法
在具体介绍Andersen算法前,例1 代码将作为流非敏感指针分析的例子,且暂不考虑在堆上分配的内存,不考虑struct、数组等结构,不考虑指针运算(如 *(p + 1))。
o = &v; // o 保存 v 的内存地址
q = &p; // q 保存 p 的内存地址
if(a > d) {
p = *q; // p 保存 p 上的内容
p = o; // p 保存 o 上的内容,即 v 的内存地址
}
*q = &w; // p 保存 w 的内存地址
通过对指针和引用的理解,流非敏感指针分析的结果如下:
其中 $p$ 为变量p的地址(内存位置),$\boldsymbol{p}$ 为指针p所指向的集合(指针变量)。
而 Anderson 算法的核心思想就是,将所有的赋值语句转为对应的约束关系,在得到所有的约束关系后,调用约束关系求解器进行求解。
2.1 Anderson算法生成约束
赋值语句和约束关系分为四种,且其他语句也可以转换为这四种基本形式。
| 赋值语句 | 约束 |
|---|---|
a = &b |
|
a = b |
|
a = *b |
|
*a = b |
: 变量的地址(内存位置)
: 指针所指向的集合(指针变量)
其他语句可以转换成这四种基本形式,如下表。
| 赋值语句 | 转换后的赋值语句 |
|---|---|
赋值语句中 的**a 表示为 *a 的指针变量,即 指针变量的指针。
2.2 约束求解
上面的例1 代码通过 Anderson算法生成的约束如下:
采用的通用框架,是指可以采用Unification算法来进行实现约束求解。
将Anderson算法生成的约束转换为标准形式,且等号右边都是递增函数。
| 约束 | 标准形式 |
|---|---|
| $$ | $$ |
其中标准形式的最后一项,由第5个约束条件推到出来。在得到标准形式后,我们可以快速推导出指针分析的结果,分析结果如下:
此外,也可以用有向图的方式,来表示约束关系,并进行求解。
将所有的变量和集合转为结点,约束关系转为有向边,约束关系中的子集为起点,约束关系中的超集为终点。约束关系的求解过程,即按有向边传递约束关系(集合关系,交汇操作),直到达到不动点。
例1 代码的约束关系,按照有向图方式的求解结果如图。
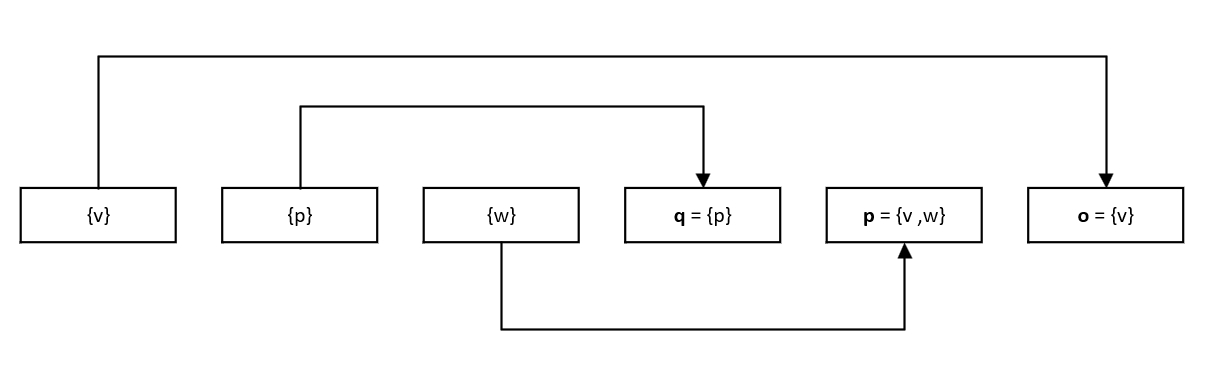
2.3 复杂度分析
对于每条边来说,前驱集合新增元素的时候该边将被激活,激活后执行时间为,其中为新增的元素数量,每条边传递的总复杂度为,其中为结点数量,边的数量为,总复杂度为。
2.4 流敏感的指针分析算法
正如2.1节中提及,Anderson算法的核心是约定好基础的赋值语句和约束的关系,同样我们可以将该思路拓展到流敏感的指针分析算法中,并在2011年的 Hardekopf B, Lin C. Flow-sensitive pointer analysis for millions of lines of code 论文中提及,采用部分SSA来对流敏感进行加速,以克服传统流敏感指针分析效率低的问题。
在数据流分析框架中,半格集合为指针变量到内存位置集合的映射,对应的交汇操作(Meet函数)为对应内存位置集合取并,流敏感的指针分析算法中赋值语句和转换函数设计如下:
| 赋值语句 | 转换函数 |
|---|---|
a = &b |
|
a = b |
|
a = *b |
对于第四种为* a = b 的赋值语句,分为两种情况,其中 条件下的转换为 Strong Update, 条件下的转换为Weak Update。
2.4 malloc问题
对于存在动态内存地址,如以下代码
在上述代码中,同样可以使用Anderson算法,不同是需要将 $malloc$ 或 $new$ 语句中分配的内存单元视为一个抽象位置,通过分配点(Call Site)的具体位置进行分配。赋值语句和转换函数为 $f(V) = V[\boldsymbol{a} \mapsto {l_V}]$,其中$l_V$为当前变量所在的语句行数。
2.5 Field-Sensitive Analysis(域敏感分析)
对于C语言中,还需要考虑指向结构体的指针;在Java语言中,需要考虑对象的字段。
采用域非敏感算法可以提供高效、不严格的指针分析结果,如将 和 抽象理解为同一个指针。反之,根据结构体的结构或者类的字段,将将其独立抽象出来,如a->next = b 可以转换为 。
3. 算法实例
3.1 Soot 分析框架
以Java的指针分析为例,采用Soot作为分析框架,实现程序内的流敏感域敏感的指针分析(flow-sensitive and domain-sensitive intra-procedural pointer analysis),项目名为 https://github.com/fe1w0/PointerAnalysis 。
Soot 的分析框架中,存在四种中间表达格式,其中主要采用Jimple中间表达格式作为分析对象,Jimple 的中间表达格式为三地址表达形式。
对于Class中的字段,Soot的相关定义是,Soot::Filed为Java Class的 字段(Field),如 <objects.A: objects.B f>,Soot::FieldRef是Field的在域(Field)上的一个具体指针。此外,Soot中间表达格式的,为当前分析的场景(保存环境信息), 是需要分析的类, 是中的函数和字段,分别为Body中的局部变量、异常处理、三地址语句。
为实现域敏感,针对上面的四种指向关系进行指针分析,并保存约束信息,实现代码见下。
for (Unit unit : jimpleBody.getUnits()) {
if (unit instanceof IdentityUnit) {
// Example r0 := @this: objects.B
// (leftValue, leftValue)
try {
Local tmpLocal = (Local) ((DefinitionStmt) unit).getLeftOp();
// System.out.println("[+] IdentityUnit (Local, Local):" + unit);
simpleAnderson.addAssignConstraints(new AssignConstraint(tmpLocal, tmpLocal));
} catch (ClassCastException classCastException) {
System.out.println("[*] ClassCastException (IdentityUnit startsWith new):" + unit);
System.out.println(classCastException);
}
} else if (unit instanceof AssignStmt) {
Value leftValue = ((DefinitionStmt) unit).getLeftOp();
Value rightValue = ((DefinitionStmt) unit).getRightOp();
if (rightValue.toString().startsWith("new")) {
// Example $r1 = new objects.B
// (leftValue, leftValue)
try {
Local tmpLocal = (Local) leftValue;
// System.out.println("[+] start with \"new\" (Local, Local):" + unit);
simpleAnderson.addAssignConstraints(new AssignConstraint(tmpLocal, tmpLocal));
} catch (ClassCastException classCastException) {
System.out.println("[*] ClassCastException (rightValue startsWith new):" + unit);
System.out.println(classCastException);
}
} else if (leftValue instanceof Local && rightValue instanceof Local) {
// Example r4 = $r0
try {
Local leftLocal = (Local) leftValue;
Local rightLocal = (Local) rightValue;
// System.out.println("[+] (Local, Local):" + unit);
simpleAnderson.addAssignConstraints(new AssignConstraint(leftLocal, rightLocal));
} catch (ClassCastException classCastException) {
System.out.println("[*] ClassCastException (Local, Local):" + unit);
System.out.println(classCastException);
}
} else if (leftValue instanceof Local && rightValue instanceof FieldRef) {
// Example $r2 = r0.<objects.A: objects.B g>
// A a = new A();
// A aa = new A();
// a -> g = new B();
// aa -> g = new B();
try {
Local leftLocal = (Local) leftValue;
FieldRef rightFieldRef = (FieldRef) rightValue;
// System.out.println("[+] (Local, FieldRef):" + unit);
simpleAnderson.addAssignConstraints(new AssignConstraint(leftLocal, rightFieldRef));
} catch (ClassCastException classCastException) {
System.out.println("[*] ClassCastException (Local, FieldRef):" + unit);
System.out.println(classCastException);
}
} else if (leftValue instanceof FieldRef && rightValue instanceof Local) {
// Example r0.<objects.A: objects.B g> = r1
try {
FieldRef leftFieldRef = (FieldRef) leftValue;
Local rightLocal = (Local) rightValue;
// System.out.println("[+] (FieldRef, Local):" + unit);
simpleAnderson.addAssignConstraints(new AssignConstraint(leftFieldRef, rightLocal));
} catch (ClassCastException classCastException) {
System.out.println("[*] ClassCastException (FieldRef, Local):" + unit);
System.out.println(classCastException);
}
} else if (leftValue instanceof FieldRef && rightValue instanceof FieldRef) {
// Example r0.<objects.A: objects.B g> = r0.<objects.A: objects.B f>
try {
FieldRef leftFieldRef = (FieldRef) leftValue;
FieldRef rightFieldRef = (FieldRef) rightValue;
// System.out.println("[+] (FieldRef, FieldRef):" + unit);
simpleAnderson.addAssignConstraints(new AssignConstraint(leftFieldRef, rightFieldRef));
} catch (ClassCastException classCastException){
System.out.println("[*] ClassCastException (FieldRef, FieldRef):" + unit);
System.out.println(classCastException);
}
} else if (leftValue instanceof Local) {
// Example r0 = 5
try {
Local leftLocal = (Local) leftValue;
// System.out.println("[+] (Local, NOT):" + unit);
simpleAnderson.addAssignConstraints(new AssignConstraint(leftLocal, leftLocal));
} catch (ClassCastException classCastException){
System.out.println("[*] ClassCastException (Local, NOT):" + unit);
System.out.println(classCastException);
}
} else if (leftValue instanceof FieldRef) {
// Example r0.<objects.A: objects.B g> = 5
try {
FieldRef leftFieldRef = (FieldRef) leftValue;
// System.out.println("[+] (FieldRef, NOT):" + unit);
simpleAnderson.addAssignConstraints(new AssignConstraint(leftFieldRef, leftFieldRef));
} catch (ClassCastException classCastException){
System.out.println("[*] ClassCastException (FieldRef, NOT):" + unit);
System.out.println(classCastException);
}
}
}
}
在约束求解部分,已获取所有的基于域敏感的约束关系,并按照Def-Use的赋值调用的顺序存储在LinkedHashSet<AssignConstraint> assignConstraints,之后按照Def-Use顺序对指针分析结果进行合并操作,最后的指针分析结果存储在LinkedHashMap<ConstraintValue, LinkedHashSet<ConstraintValue>> constraintsResults中,从而实现流敏感分析,代码见下。
void solver() {
// System.out.println(printValues());
try {
for (AssignConstraint assignConstraint : assignConstraints) {
if (assignConstraint.fromConstraintValue.equals(assignConstraint.toConstraintValue)){
LinkedHashSet<ConstraintValue> tmpValues = new LinkedHashSet<ConstraintValue>();
tmpValues.add(assignConstraint.toConstraintValue);
constraintsResults.put(assignConstraint.toConstraintValue, tmpValues);
} else {
if (!constraintsResults.containsKey(assignConstraint.toConstraintValue)) {
// to 之前不存在
LinkedHashSet<ConstraintValue> tmpValues = new LinkedHashSet<ConstraintValue>();
tmpValues.add(assignConstraint.toConstraintValue);
if (constraintsResults.containsKey(assignConstraint.fromConstraintValue)) {
// from 之前已经有保存 constraintsResults.containsKey。
for (ConstraintValue tmpValue : constraintsResults.get(assignConstraint.fromConstraintValue)) {
if (!tmpValues.contains(tmpValue)) {
tmpValues.add(tmpValue);
}
}
} else {
// from 之前没有保存
tmpValues.add(assignConstraint.fromConstraintValue);
}
constraintsResults.put(assignConstraint.toConstraintValue, tmpValues);
} else {
// to 之前存在
if (constraintsResults.containsKey(assignConstraint.fromConstraintValue)) {
// from 之前已经有保存
for (ConstraintValue tmpValue : constraintsResults.get(assignConstraint.fromConstraintValue)) {
if ( !(constraintsResults.get(assignConstraint.toConstraintValue)).contains(tmpValue)) {
(constraintsResults.get(assignConstraint.toConstraintValue)).add(tmpValue);
}
}
} else {
// from 之前没有保存
(constraintsResults.get(assignConstraint.toConstraintValue)).add(assignConstraint.fromConstraintValue);
}
}
}
}
} catch (Exception exception) {
System.out.println("[*] Solver Failed.");
System.out.println(exception);
}
}
3.2 算法应用
根据以上设计思路,对以下代码进行分析,首先利用Soot分析框架,自上而下读取每一条语句,根据语句的语法设置对应的约束条件,并传递给约束求解器。
public class A {
// Object A with attributes of type B
public int i = 5;
public B f = new B();
public B g = new B();
public B h;
public A(B b) {
this.f = b;
this.g = this.f;
}
}
约束求解器得到以下分析结果,可得到r0.<objects.A: objects.B g> 和 r0.<objects.A: objects.B g> 为别名对象等结论。
---------------Analysis Result (objects.A.<init>.<objects.A: void <init>(objects.B)>):
r0(objects.A) : r0(objects.A)
r3(objects.B) : r3(objects.B)
r0.<objects.A: int i> : r0.<objects.A: int i>
$r1(objects.B) : $r1(objects.B)
r0.<objects.A: objects.B f> : r0.<objects.A: objects.B f> $r1(objects.B) r3(objects.B)
$r2(objects.B) : $r2(objects.B)
r0.<objects.A: objects.B g> : r0.<objects.A: objects.B g> $r2(objects.B) $r4(objects.B) r0.<objects.A: objects.B f> $r1(objects.B) r3(objects.B)
$r4(objects.B) : $r4(objects.B) r0.<objects.A: objects.B f> $r1(objects.B) r3(objects.B)
4. 总结
本文中主要对Andersen算法进行详细介绍,此外也可用CFL(上下文无关文法)对指针分析问题进行分析,同时基于CFL和基于Anderson算法的域敏感分析具有等价性。从The Ant and the Grasshopper: Fast and Accurate PointerAnalysis for Millions of Lines of Code论文中指出,Steensgaard算法与Andersen算法相比较,得益于通过合并结点避免传递的方式,复杂度降到,但对分析精度产生了部分牺牲。